前言
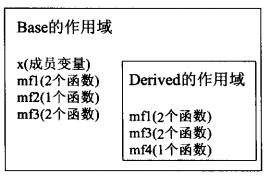
我们只能继承virtual和non-virtual函数,而重新定义一个non-virtual函数永远是错误的。所以本节讨论只基于”继承一个带有默认实参的virtual函数”。之所以需要讨论它,是因为virtual函数动态绑定,但默认实参静态绑定。
静态绑定与动态绑定
静态类型与动态类型
对象所谓的静态类型(static type),就是它在程序中被声明为的类型。举例而言:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class shape{
public:
enum color{red,green,blue};
virtual void draw(color c = red) const = 0;
};
class rectangle:public shape{
public:
virtual void draw(color c = green) const;//重定义了默认实参
};
class circle:public shape{
public:
virtual void draw(color c) const;
//当客户通过对象调用此函数时必须使用实参,因为静态绑定不从base继承默认实参
//但若以指针或引用调用则无需如此,因为动态绑定下该函数会从其base获取默认实参
}
此继承体系如图所示: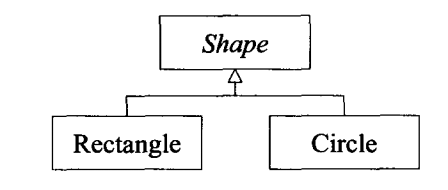
那么考虑这些指针:1
2
3shape* ps;//静态类型为shape*
shape* pc = new circle;//同上
shape* pr = new rectangle;//同上
它们都被声明为pointer-to-shape类型,所以他们的静态类型都是shape*。
动态类型则是指目前所指对象的类型,也就是说,动态类型可以表现出一个对象将会有怎样的行为。
动态类型一如其名,可以在程序执行过程中改变:1
2ps=pc;//ps的动态类型改为Circle*
ps=pr;//ps的动态类型改为Rectangle*
动态绑定与静态绑定
virtual函数本身通过动态绑定来执行(也就是说如何执行取决于对象的动态类型),但如果遇到了带有默认实参的virtual函数,这个时候问题来了。
virtual是动态绑定,而缺省参数值却是静态绑定。也就是说,你可能会在调用“一个定义于derived class内的virtual函数”的同时却使用了base class为它指定的缺省参数,举例而言,1
2pr->draw();//以为此时的默认实参是green
//但其实等价于调用rectangle::draw(shape::red);
何种原因造成了这种分裂机制
C++将默认实参设为静态绑定的原因在于运行期效率。如果缺省参数设置为动态绑定,那么编译器就必须在运行期为virtual函数决定适当的参数缺省值,而静态绑定在编译期就完成了决定。动态绑定默认实参过于缓慢和复杂。
解决方案
就算严格遵守了本节所讲的内容,也未必就称得上最佳设计:1
2
3
4
5
6
7
8
9class shape{
public:
enum color{red,green,blue};
virtual void draw(color c = red) const = 0;
};
class rectangle:public shape{
public:
virtual void draw(color c = red) const;//不再重定义
};
这种写法无疑造成了代码重复。更为重要的是,代码重复造成了相依性:一旦作为base class的Shape内的默认实参需要改变,则所有derived class都必须发生改变,否则就造成了重定义默认实参。因此我们必须考虑某种替代手法。
NVI
1 | class Shape{ |
由于non-virtual不会被覆写,所以derived class继承得到的函数必然具备与base class相同的默认实参。
总结
禁止重定义默认实参,因为它们是静态绑定,而virtual函数是动态绑定。