前言
C++允许重载标题所提及的三种操作符,但本节禁止其重载的原因很简单,易于引发歧义或者说与预期设想不符。
“&&”、”||”
众所周知,&&与||具备短路特性。当你重载&&或者||以后,你以函数调用代替了短路求值。
这样会造成两个缺点:
- 函数调用需要计算所有参数,你的表达式不再具备短路特性。
- c++没有规定函数参数的计算顺序,最终表达式结果由编译器决定。
“,”
一个包含逗号的表达式首先计算逗号左边的表达式,然后计算逗号右边的表达式;整个表达式的结果是逗号右边表达式的值。自定义的operator,没有这样的特性,最终结果由编译器决定。
禁止重载的操作符
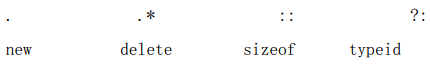
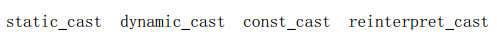
允许重载的操作符

总结
操作符重载的目的是为了令程序更容易阅读,书写和理解,而不是炫耀技巧。如果没有重载操作符的必要,就不要重载。