前言
在C++对象中,data member分为两种:
- static
- non-static
function member分为三种:
- static
- non-static
- virtual
已知Point class声明如下:1
2
3
4
5
6
7
8
9
10
11class Point{
public:
Point(float xval);
virtaul ~Point();
float x() const;
static int PointCount();
protected:
virtual ostream& print(ostream &os) const;
float _x;
static int _point_count;
};
我们应该以何种策略塑模出data member及function member?
简单对象模型
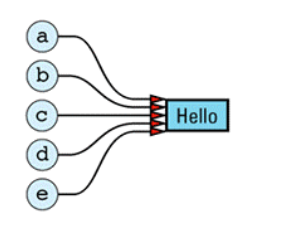
简单对象模型是了尽量降低C++编译器的复杂程度而开发出来的,并且因此付出了空间损耗增加与执行效率降低的代价。在这个简单模型中,一个object是一组slots,每一个slot指向了一个memeber: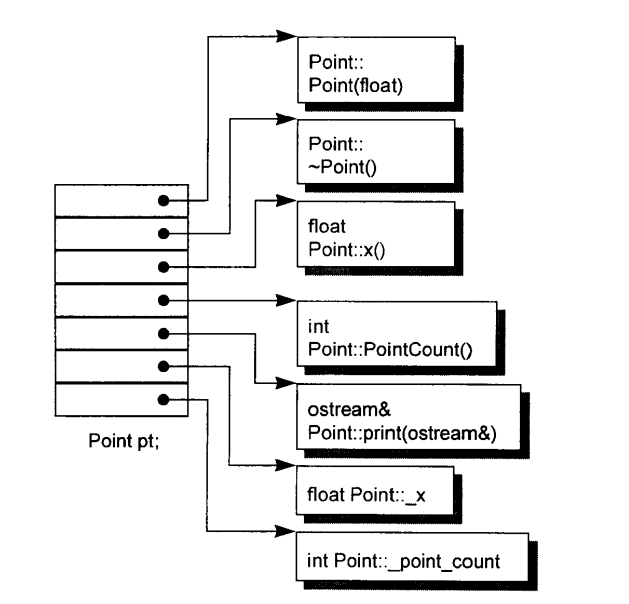
在该简单对象模型中,member本身不并在对象内,仅有指向member的指针才位于对象内,这样保证了对象内部只需要存放一种数据类型:指针。显然,对象的大小等于member数量*指针大小。
尽管这种模型并不应用于实际生产,不过这种理念倒是被做成了某种设计手法:pimpl,或者Bridge设计模式。
表格驱动式对象模型
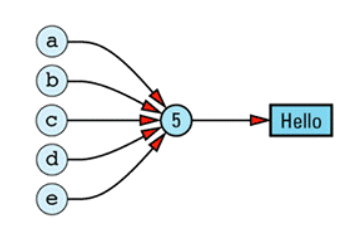
为了保证所有classes的objects均具有一致的表达方式,另一种对象模型的做法是:将所有与members相关的信息抽离出来,放在一个member data table与member function table之中。member data table直接持有数据,member function table则是一系列slots,每一个slots指向一个member function: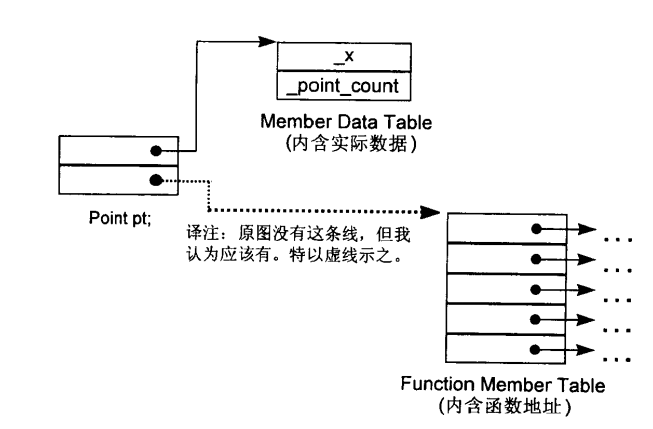
虽然这种模型也没有应用于直接生产,但member function table的观念却成为了支撑virtual function的一个有效方案。
C++对象模型
不考虑继承
C++对象模型由简单对象模型演化而来,并对内存空间及存储时间做出了优化。
在此模型中,non-static data members被配置于object之内,static data members则被存储于所有objects之外。static or non-static function members也都被存储于objects之外。
virtual function以两个步骤实现:
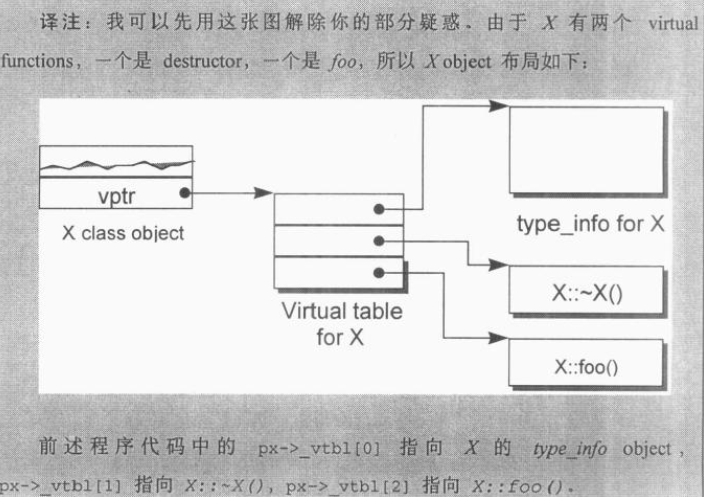
- 每一个clss产生一堆指向virtual functions的指针,用一个表格存放之,该表格也被成为虚函数表(vtbl)。虚函数表的第一个slot存放着当前class所对应的type_info object。(RTTI)
- 每一个object内部都存有指向vtbl的指针vptr,vptr的setting与resetting由构造、析构、拷贝赋值运算符自动完成。
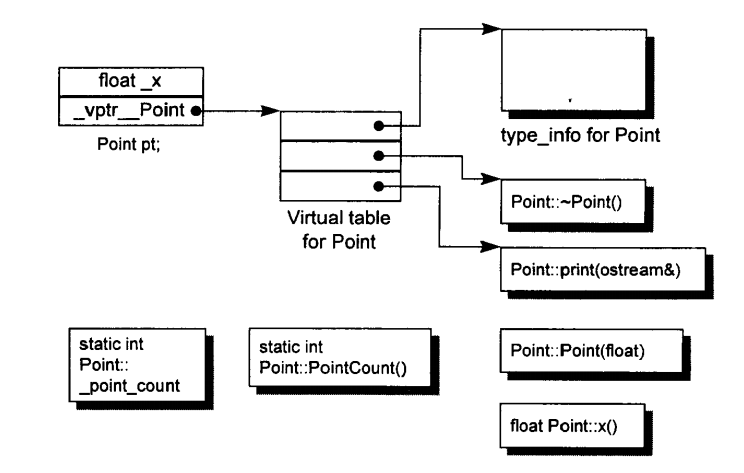
该模型的优势主要在于空间与存储时间的效率,但缺陷也很明显:non-static data members一旦有所修改,应用程序就需要重新编译。在编译弹性方面,上一小节所提及的双表格模型就做的很好。
加入继承
C++支持单一继承与多重继承,甚至,继承关系也可以指定为virtual(可以理解为共享):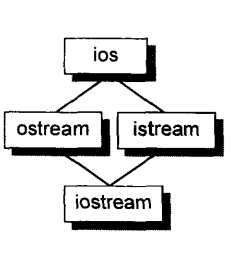
在虚继承的情况下,base class无论在继承体系中被派生多少次,其永远只会存在一个实体(subobject),例如iostream中就只有一个virtual ios base class的实体。
derived class塑模base class实体
在简单对象模型中,每一个base class可以被derived class object内的slot指出,该体系的缺点是:因为间接性导致空间和存取时间需要额外开销,优点在于class object不会因其base class发生改变而受到影响。
base class table模型:base class table被产出后,表中的每一个slot内含一个base class地址,就如同vtbl内含virtual function的地址一般。每一个class含有一个bptr,指向其base class table。该体系的缺点在于:因为间接性导致空间和存取时间需要额外开销。优点在于每一个class object对于继承都有一致的表现方式:每一个class object的固定位置都有一个base table指针,与base classes的大小或数目无关。此外,无需改变class objects本身,就可以放大、缩小、或更改base class table。
下图展示了ios继承体系在base class table下的对象模型: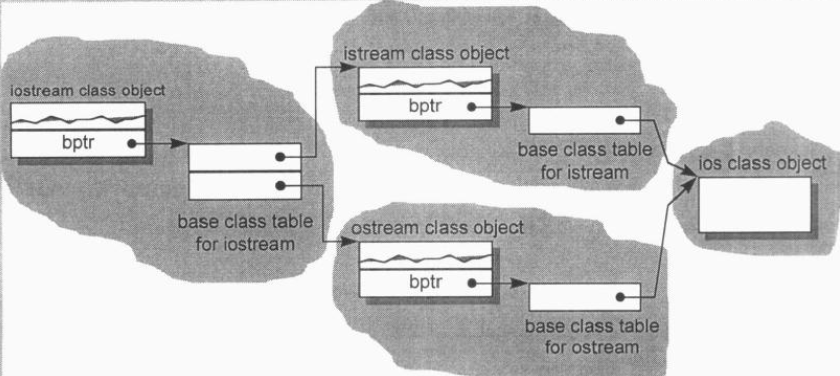
不管哪一种对象模型,“间接性”总是随着继承体系深度的增长而增加,也就是存取操作的时间会增长。当然,derived class可以多放置一些指针,指向继承体系中的每一个base class,但这付出了空间成本。
C++最初采用的对象模型不具备任何间接性:base class subobject的data member被直接置于derived class中,这保证了高效存取,缺点在于base class一旦发生改动,整个继承体系都必须重新编译。
virtual base class的导入增加了间接性,其原始模型是在class objects中为每一个有关联的virtual base class加上一个指针。其他模型无非是两种情况:导入一个virtual base class table,又或者扩充vtbl,在其中放入virtual base class的地址。
对象模型如何影响程序
不同对象模型,会导致如下两个结果:
- 现有程序必须修改
- 必须加入新的程序
实例
假设现有class X,定义有copy constructor,virtual destructor,以及一个virtual function foo,考虑如下函数:1
2
3
4
5
6
7
8X foobar(){
X xx;
X *px = new X;
xx.foo();
px->foo();
delete px;
return xx;
}
该函数可能会在内部被转化为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void foobar(X &_result){
//构造_result并取代local xx
_result.X::X();
//转化new语句
px = _new(sizeof(X));
if(px)
px->X::X();
//执行非虚函数
foo(&_result);
//执行虚函数
(*px->vtbl[2])(px);
//转化delete语句
if(px){
(*px->vtbl[1](px));
_delete(px);
}
//不需要摧毁local object xx
return;
}
这就是对象模型将实际代码转化后的一个可能实例,其解释可见后续诸章,下图给出了部分注解: