前言
1 | Point3d origin; |
可能会有人好奇x的存取成本有多大,答案是视Point3d与x如何声明而定,x可能是一个static member或者nonstatic。Point3d可能是一个独立的class,也可能从另一个单一的base class派生而来,甚至可能是从多重继承或虚拟继承而来,下面将依次介绍这几种情况。
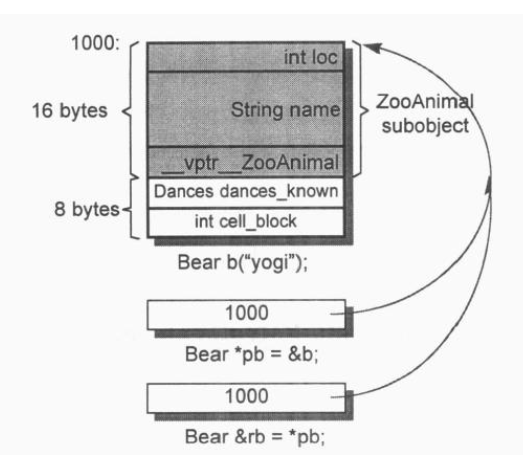
在探究之前,我们再次抛出一个问题:从object本身存取data member与从指向object的指针存取data member有何差异:1
2Point3d origin,*pt = &origin;
origin.x = 0.0;pt->x = 0.0;
在本节结束前我们将回答这个问题。
static data members
Static data members被编译器提出于class之外,并被视为一个global变量(只在class生命范围之内可见)。每一个member的存取access level,以及与class的关联性,并不会导致任何空间或时间的额外负担。
指针存取与对象存取
每一个static data member仅具备一个实体,存放于程序的data segment之中,每次程序存取static member都会被编译器视为该extern实体的存取操作:1
2origin.chunkSize=250;//Point3d::chunkSize=250;
pt->chunkSize=250;//Point3d::chunkSize=250;
这是C++语言中“通过一个指针与直接操作对象存取member,效果完全一样”的唯一情况。造成这种情况的原因在于.操作符根本并没有进入object内部获取数据。如果该static data member从复杂继承关系中继承而来,并不影响这个结论的正确性,因为static data member仅仅具备一个实体,其存取路径不受任何继承关系影响。
函数调用存取
如果static data member的存取经由函数调用而被存取,如果我们写:1
foobar().chunkize=250;
调用foobar()时会发生什么?(foobar()的结果并不能改变static member,作者的意思在于查看编译器在此处是否存在优化)
在C++ pre-Standard规格中,ARM(Annotated Reference Manual)并未指定foobar()是否必须被evaluated。但C++ Standard明确要求foobar()必须被evaluated,虽然其结果并无用处:1
2(void) foobar();//evaluate expression,discarding result
Point3d.chunkSize()=250;
名变换
若取一个static data member的地址,会得到一个指向其数据类型的指针,而不是一个指向其class member的指针,因为static member并不内含在一个class object之中,这一点十分显然。
但如果有两个classes,每一个都声明了一个static member freeList,那么当它们都置于程序的data segment内部时会出现名称冲突。编译器的解决方法是暗中对每一个static data member编码(name-mangling,名变换)。名变换具备两个特点:
- 每一种算法对应一种独一无二的名字
- 编译系统如果需要与开发者进行交互,这些名称可以被轻易推导回原有名称。
Nonstatic Data Members
Nonstatic Data Members与object
Nonstatic Data Members存在于class object内部,除非经由explicit/implicit class object,没有办法直接存取它们。只要我们试图在某个member function中直接处理一个nonstatic data member,那么implicit class object就一定会发生:1
2
3
4
5void Point3d::translate(const Point3d &pt){
x+=pt.x;
y+=pt.y;
z+=pt.z;
}
实质上这一系列操作都是通过this指针完成,其函数的真正表示形式大致如下:1
2
3
4
5void Point3d::translate(point3d *const this,const Point3d &pt){
this->x+=pt.x;
this->y+=pt.y;
this->z+=pt.z;
}
nonstatic data members的存取
如果需要对一个nonstatic data member进行存取操作,那么编译器需要获取当前object的地址,然后通过偏移量计算出data member的地址,举例而言:1
&origin+(&Point3d::_y-1);
-1操作是其中的重点。指向data member的指针,其offset的值总是被加上1,这样就可以让编译器区分出“一个指向data member的指针,用以指出class的第一个member”,以及“一个指向class object的指针”两种情况。
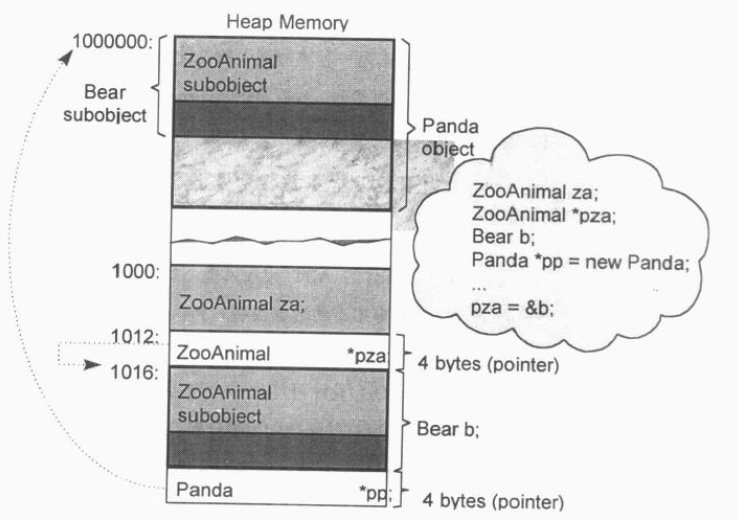
nonstatic data member与继承
每一个nonstatic data member的offset在编译期间便已得知,甚至如果member属于一个base class subobject也是一样,因此,存取一个nonstatic data member的效率等价于存取一个C struct member或一个nonderived class的member。
虚继承
虚继承为数据的存取导入了一层间接性,例如:1
2Point3d *pt3d;
pt3d->_x = 0.0;
如果_x是一个virtual base class的member,存取速度相较于其他情况要慢一点,其具体原因可见后续章节(继承对于对象布局的影响)。
我们回到本节一开始时提出的问题:通过对象存取与通过指针存取有多大的差别?1
2origin.x = 0.0;
pt->x = 0.0;
如果继承体系中存在一个virtual base class,且被存取的member是一个从virtual base class继承得到的member时,上述两种写法存在较大差异。因为在此时我们无法确定pt必然指向哪一种class type(因此我们也就不知道编译期这个member真正的offset),因此该存取操作必然需要被延后到执行期,经由一个额外的间接引导。但如果使用对象则不存在这种问题,因为静态类型早已绑定,其offset也早已在编译期确定。一个优秀的编译器甚至能够静态地经由origin解决对x的存取。