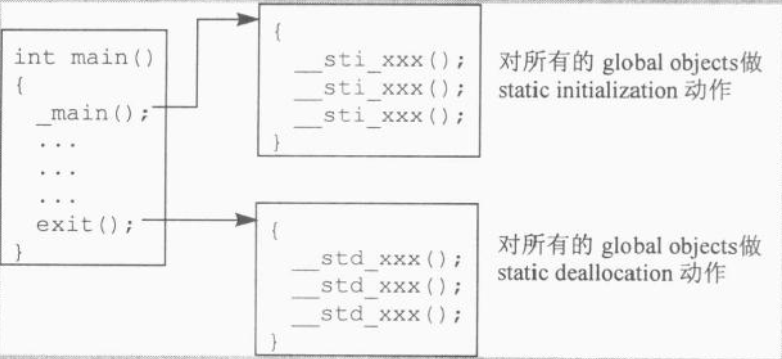
前言
原本Template被视为对container的一项重要支持,但其现在已经成为了通用程序设计的基石。它也被用于属性混合或互斥机制的参数化技术中,此外,TMU的发现,使得程序效率得到了巨大的提升。
然而,template也是C++最为困难的主题。本节将重点描述template,以下是三个主要讨论方向:
- template声明
可以理解为当你声明一个template class或template class member function时会发生什么。 - 如何具现出class object以及inline nonmember,以及member template function
上述的这些每一个编译单位都将拥有一份实体 - 如何具现出nonmember以及static template class members
上述的这些每一个可执行文件中仅会存在一个实体。
Template的具现行为
现有Template Point class如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14template<typename Type>
class Point{
public:
enum Status {unallocated,normalized};
Point(Type x=0.0,Type y=0.0,Type z=0.0);
~Point();
void* operator new(size_t);
void operator delete(void*,size_t);
//...
private:
static Point<Type> *freeList;
static int chunkSize;
Type _x,_y,_z;
};
当编译器看到template class声明时,不会执行任何操作。因此,上述的static data members并不可用。虽然enum Status的真正类型在所有Point instantiations中都一样,但它们只能通过template Point class的某个实体来存取或操作,因此我们可以这样写:1
Point<float>::Status s;
而不能写为:1
Point::Status s;
static data member亦是如此。
如果我们定义一个指针指向特定的实体:1
Point<float> *ptr =nullptr;
也不会生成或执行任何操作。我们需要明确,一个指向class object的指针,本身并不是一个class object,编译器不需要知道任何与class相关的任何members数据或object布局数据,因此没有将某个template具现的必要。C++ standard禁止编译器对此情况作出具现化操作。
但如果是一个reference,那它真的会具现化出一个class,原因在于reference必须要绑定某个真正存在的对象。
假若我们明确定义表达式导致某个template class发生具现化:1
const Point<float> origin;
在此情况下,float instantiation的真正对象布局被产生出来,回顾之前的声明我们可以得知,origin的配置空间需要足够容纳3个float成员。
然而,member functions(未使用过的)不应该被具现化,它们应当仅仅在被使用时才会发生具现化。之所以需要这个规则,主要出于两个原因:
- 时间与空间效率
如果某个class存在大量的member functions,而真正具现化出的某些class只使用了其中的一部分,那么全部具现化会造成一种性能上的浪费。 - 尚未实现的机能
template class中定义的所有member functions并不一定适用于所有的Type,如果只具现那些真正使用到的member functions,那么template就能支持那些原本可能会造成编译器错误的类型。
Template的错误报告
1
2
3
4
5
6
7
8
9template <class T>
class Mumble{
public:
Mumble(T t=1024):tt(t){
if(tt!=t) throw ex;
}
private:
T tt;
};
这个Template的声明存在下述错误:
- t被初始化为整数常量1024,其可行程度视真实类型而定。
- !=运算符可能尚未被定义,需要视实际使用情况而定。
上述的两个潜在错误只能在具现操作完成后才能被发现,就目前的编译器而言,面对template声明只能执行有限的错误检查。Nonemember与member template functions在具现行为发生之前一样没有完全的类型检验,这直接导致了一些十分露骨的template错误声明居然能够通过编译,例如:1
2
3
4
5
6
7
8
9
10
11
12template <typename type>
class Foo{
public:
Foo();
type val();
void val(type v);
private:
type _val;
}
//以下内容不会触发报错
template <typename type>
double Foo<type>::bogus_member() {return this->dbx;}//即使Foo并没有member function与data
Template中的名称决议方式
在讲本小节之前,我们首先需要明确两种定义:
- scope of the template defintion
定义出template的程序,有实例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15extern double foo(double);
template<class type>
class ScopeRules{
public:
void invariant(){
_member = foo(_val);
}
type type_dependent(){
return foo(_member);
}
//...
private:
int _val;
type _member;
}; - scope of the template instantiation
具现出template的程序:1
2
3extern int foo(int);
//...
ScopeRule<int> sr0;
在ScopeRules template中有两个foo()调用操作,在”scope of template definition”中,只有一个foo()函数声明位于scope内,然而在”scope of template instantiation”中,两个foo()函数声明都位于scope之内,如果我们使用了一个函数调用操作:1
sr0.invariant();//调用哪一个foo()?
本次调用操作存在两个函数可以调用,分别为:1
2
3
4//scope of the template declaration
extern double foo(double);
//scope of the template instantiation
extern int foo(int);
因为_val的类型是int,那么很多人会认为实际调用的是int,然而,调用的是double。
Template中,对于一个nonmember name的决议结果是根据这个name的使用与否与“用以具现出该template的参数类型”有关而决定的。如果其使用互不相关,那么就以“scope of the template declaration”来决定name,反之则使用“scope of the template instantiation”。
在刚才的实例中,foo()与用以具现ScopeRules的参数类型无关,因为_val是一个int,一个类型不会根据不同的具现化而发生改变的数据,因此,member的类型并不会影响哪一个foo()被选中,所以编译器会选择double(在该scope中,只有一个foo()候选者)。
我们再次给出一个实例,该实例内容为:1
sr0.type_dependent();//调用哪一个foo()?
这一次由于参数类型相关,当前候选域内有2个foo()候选者,int类型与当前类型一致,因此得以被选中。
上述两个实例表明编译器必须保持两个scope contexts:
- “scope of the template declaration”,用以专注于一般的template class。
- “scope of the template instantiation”,用以专注于特定的实体。
Member Function的具现行为
template的具现化大致来说有两种策略:
- 编译时期策略,程序代码必须在program text file中备妥可用。
链接时期策略,通过某些工具导引编译器的具现化行为。
接下来作者描述了如何具现化template function。