前言
最近在学习velox orderby算子,其排序存在一个列转行的过程,其中行数据的表现形式是RowContainer。
本节主要描述RowContainer的layout和基础api。
笔者当前仅关注SortBuffer所需要关注的部分,对于RowContainer的其他部分(aggregate、join等),将在后续补充。
RowContainer
RowContainer是velox用于存储行数据的数据结构,当前用于agg、hash join、orderby三种场景。
其内存占用分为 定长部分 + 变长部分。
定长部分:total(sizeof(columnTypeKind)) + flag + 变长数据长度(若存在),由`memory::AllocationPool管理。
变长部分:变长数据,由HashStringAllocator管理。
相关源码位置:1
2velox/exec/RowContainer.h
velox/exec/RowContainer.cpp
Ctor
在SortBuffer中,RowContainer的构造函数调用如下:
也就是只需要传入keyTypes,dependentTypes,pool三个参数即可。
其中keyTypes是key列(用于排序的列)类型,dependentTypes是非排序列类型。
1 | RowContainer( |
精简版构造函数与所需要关注的数据结构如下(去除了agg、hash join相关的部分):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58RowContainer::RowContainer(
const std::vector<TypePtr>& keyTypes,
const std::vector<TypePtr>& dependentTypes,
memory::MemoryPool* pool)
: keyTypes_(keyTypes),
stringAllocator_(std::make_unique<HashStringAllocator>(pool)),
rows_(pool) {
int32_t offset = 0;
int32_t nullOffset = 0; // bit维度
bool isVariableWidth = false;
for (auto& type : keyTypes_) { // 排序列排在前面,对缓存友好
typeKinds_.push_back(type->kind());
types_.push_back(type);
offsets_.push_back(offset);
offset += typeKindSize(type->kind());
nullOffsets_.push_back(nullOffset); // bit维度
isVariableWidth |= !type->isFixedWidth(); // 当前行是否存在可变长字段
++nullOffset;
columnHasNulls_.push_back(false); // 某一列是否存在null
}
// 已记录完所有key列offset,修正offset,使其至少和一个指针大小相等
offset = std::max<int32_t>(offset, sizeof(void*));
const int32_t firstAggregateOffset = offset;// 此offset紧贴key列最后一个数据
for (auto& type : dependentTypes) {
types_.push_back(type);
typeKinds_.push_back(type->kind());
nullOffsets_.push_back(nullOffset);
++nullOffset;
isVariableWidth |= !type->isFixedWidth();
columnHasNulls_.push_back(false);
}
// Free flag.
nullOffsets_.push_back(nullOffset); // free flag offset,表示这一行是否已被删除
freeFlagOffset_ = nullOffset + firstAggregateOffset * 8; // 修正为bit维度
++nullOffset;
flagBytes_ = bits::nbytes(nullOffsets_.back() + 1); // flag占据了多少个字节,对于orderby来说,就是(列数 + 1(free flag))/8向上取整
for (int32_t i = 0; i < nullOffsets_.size(); ++i) { // 修正flag offset为bit维度
nullOffsets_[i] += firstAggregateOffset * 8;
}
offset += flagBytes_; // 将flag占据的字节加入offset,由此看出,flag贴在key列后面
for (auto& type : dependentTypes) { // 追加dependent offset
offsets_.push_back(offset);
offset += typeKindSize(type->kind());
}
if (isVariableWidth) { // 若当前行中存在可变长字段
rowSizeOffset_ = offset; // 当前行总变长数据长度offset
offset += sizeof(uint32_t); // 用于存储变长数据长度
}
fixedRowSize_ = bits::roundUp(offset, alignment_); // 对齐之后的行长度, 默认按1对齐,最终将按此值申请行内存
for (auto i = 0; i < offsets_.size(); ++i) {
// 将data offset和null offset绑定,编码为一个uint64_t, 用于快速访问
// 其中高32位为data offset,低32位为null offset
rowColumns_.emplace_back(
offsets_[i],
(nullableKeys_ || i >= keyTypes_.size()) ? nullOffsets_[i]
: RowColumn::kNotNullOffset);
}
}
Layout
根据上述构造函数,用于orderby的RowContainer的layout大致如下:1
[key1][key2]...[keyN][padding](if needed)[flag][dependent1][dependent2]...[dependentN][variable length data](if needed)
example
假设当前行结构如下:1
2
3
4
5
6key1: INT(4 bytes)
dependent1: BIGINT(8 bytes)
dependent2: SMALL(2 bytes)
dependent3: REAL(4 bytes)
dependent4: DOUBLE(8 bytes)
dependent5: VARCHAR(16 bytes)
则有offsets数组如下:1
2offsets_: [0, 9, 17, 19, 23, 31]
nullOffsets_: [64, 65, 66, 67, 68, 69, 70]
数据布局图大致如下: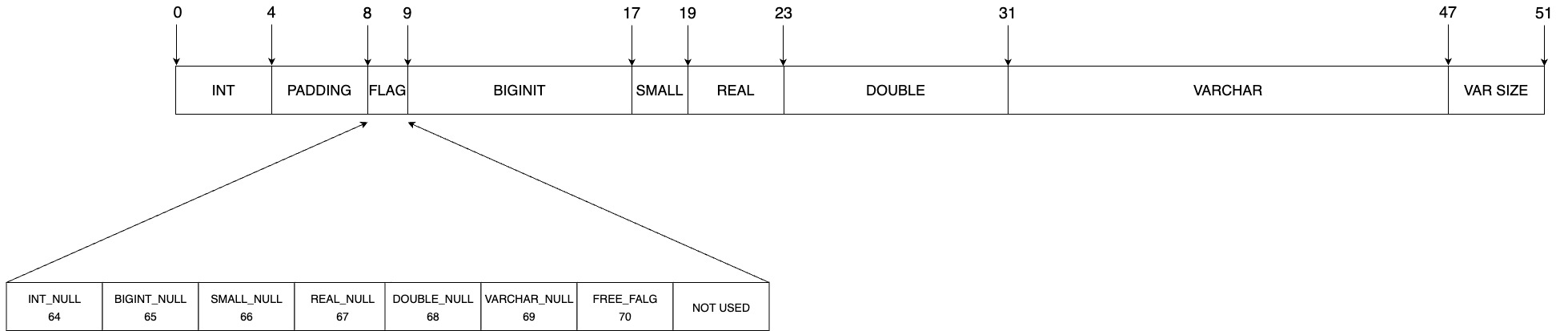
API
newRow
获取新行内存,返回一个char*指针,指向新行的内存地址。
此api未必触发内存分配与获取,可能会返回已删除的行 内存地址(即每一次erase并不真正释放内存)。
1 | char* RowContainer::newRow() { |
initializeRow
初始化行数据。
1 | char* RowContainer::initializeRow(char* row) { |
store
将列数据存储数据到行中。
调用方式:1
2
3
4
5
6
7
8
9
10
11
12
13
14SelectivityVector allRows(input->size()); // 这里使用只是为了适配store api
std::vector<char*> rows(input->size());
for (int row = 0; row < input->size(); ++row) {
rows[row] = data_->newRow();
}
auto* inputRow = input->as<RowVector>();
for (const auto& columnProjection : columnMap_) { // columnMap_存储有列转行时的映射关系,因为行存储时key列排在前面
DecodedVector decoded(
*inputRow->childAt(columnProjection.outputChannel), allRows);
data_->store(
decoded,
folly::Range(rows.data(), input->size()),
columnProjection.inputChannel);
}
接口实现:
将decoded中的前rows.size个值存储到rows的columnIndex列中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28void RowContainer::store(
const DecodedVector& decoded,
folly::Range<char**> rows,
int32_t column) {
VELOX_CHECK_GE(decoded.size(), rows.size());
const bool isKey = column < keyTypes_.size();
if ((isKey && !nullableKeys_) || !decoded.mayHaveNulls()) {
VELOX_DYNAMIC_TYPE_DISPATCH( // 无需关注null
storeNoNullsBatch,
typeKinds_[column],
decoded,
rows,
isKey,
offsets_[column]);
} else {
const auto rowColumn = rowColumns_[column];
VELOX_DYNAMIC_TYPE_DISPATCH_ALL(
storeWithNullsBatch,
typeKinds_[column],
decoded,
rows,
isKey,
rowColumn.offset(),
rowColumn.nullByte(),
rowColumn.nullMask(),
column);
}
}
宏展开后大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
VELOX_DYNAMIC_TYPE_DISPATCH_IMPL(TEMPLATE_FUNC, , typeKind, __VA_ARGS__)
[&]() {
switch (typeKinds_[column]) {
case ::facebook::velox::TypeKind::BOOLEAN: {
return storeNoNullsBatch<::facebook::velox::TypeKind::BOOLEAN>(
decoded, rows, isKey, offsets_[column]);
}
case ::facebook::velox::TypeKind::INTEGER: {
return storeNoNullsBatch<::facebook::velox::TypeKind::INTEGER>(
decoded, rows, isKey, offsets_[column]);
}
case ::facebook::velox::TypeKind::TINYINT: {
return storeNoNullsBatch<::facebook::velox::TypeKind::TINYINT>(
decoded, rows, isKey, offsets_[column]);
}
...
}
[&]() { \
if ((typeKind) == ::facebook::velox::TypeKind::UNKNOWN) { \
return TEMPLATE_FUNC<::facebook::velox::TypeKind::UNKNOWN>(__VA_ARGS__); \
} else if ((typeKind) == ::facebook::velox::TypeKind::OPAQUE) { \
return TEMPLATE_FUNC<::facebook::velox::TypeKind::OPAQUE>(__VA_ARGS__); \
} else { \
return VELOX_DYNAMIC_TYPE_DISPATCH_IMPL( \
TEMPLATE_FUNC, , typeKind, __VA_ARGS__); \
} \
}()
[&]() {
if ((typeKinds_[columnIndex]) == ::facebook::velox::TypeKind::UNKNOWN) {
return storeNoNullsBatch<::facebook::velox::TypeKind::UNKNOWN>(
decoded,
rowIndex,
isKey,
row,
rowColumn.offset(),
rowColumn.nullByte(),
rowColumn.nullMask(),
columnIndex);
} else if ((typeKinds_[columnIndex]) == ::facebook::velox::TypeKind::OPAQUE) {
return storeNoNullsBatch<::facebook::velox::TypeKind::OPAQUE>(
decoded,
rowIndex,
isKey,
row,
rowColumn.offset(),
rowColumn.nullByte(),
rowColumn.nullMask(),
columnIndex);
} else {
return [&]() {
switch (typeKinds_[columnIndex]) {
case ::facebook::velox::TypeKind::BOOLEAN: {
return storeNoNullsBatch<::facebook::velox::TypeKind::BOOLEAN>(
decoded,
rowIndex,
isKey,
row,
rowColumn.offset(),
rowColumn.nullByte(),
rowColumn.nullMask(),
columnIndex);
}
case ::facebook::velox::TypeKind::INTEGER: {
return storeNoNullsBatch<::facebook::velox::TypeKind::INTEGER>(
decoded,
rowIndex,
isKey,
row,
rowColumn.offset(),
rowColumn.nullByte(),
rowColumn.nullMask(),
columnIndex);
}
...
}
}
}
}
其中storeNoNullsBatch有实现如下:1
2
3
4
5
6
7
8
9
10
11// 即对每一行的第columnIndex列调用storeNoNulls
template <TypeKind Kind>
inline void storeNoNullsBatch(
const DecodedVector& decoded,
folly::Range<char**> rows,
bool isKey,
int32_t offset) {
for (int32_t i = 0; i < rows.size(); ++i) {
storeNoNulls<Kind>(decoded, i, isKey, rows[i], offset);
}
}
storeNoNulls实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16template <TypeKind Kind>
inline void storeNoNulls(
const DecodedVector& decoded,
vector_size_t rowIndex,
bool isKey,
char* row,
int32_t offset) {
using T = typename TypeTraits<Kind>::NativeType;
if constexpr (std::is_same_v<T, StringView>) { // 针对变长数据,需要记录行变长数据总长度
RowSizeTracker tracker(row[rowSizeOffset_], *stringAllocator_);
stringAllocator_->copyMultipart(
decoded.valueAt<T>(rowIndex), row, offset); // copy和存储stringview
} else {
*reinterpret_cast<T*>(row + offset) = decoded.valueAt<T>(rowIndex); // 定长数据直接拷贝至对应位置
}
}
listRows
提取各行地址至指定位置。
调用方式:1
2
3sortedRows_.resize(numInputRows_);
RowContainerIterator iter; // 适配接口
data_->listRows(&iter, numInputRows_, sortedRows_.data());
实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61// 从iter位置开始,提取 maxRows行数据 && 提取maxBytes字节数据 至 rows
// 返回实际提取行数
// 对于默认构造的迭代器,从头开始提取
// 并不执行实际的数据拷贝,只是将包含了 maxRows || maxBytes 行的行地址存储到rows中
int32_t listRows(
RowContainerIterator* iter,
int32_t maxRows,
uint64_t maxBytes,
char** rows) const {
return listRows<ProbeType::kAll>(iter, maxRows, maxBytes, rows);
}
int32_t listRows(RowContainerIterator* iter, int32_t maxRows, char** rows)
const {
return listRows<ProbeType::kAll>(iter, maxRows, kUnlimited, rows);
}
int32_t
listRows(
RowContainerIterator* iter,
int32_t maxRows,
uint64_t maxBytes,
char** rows) const {
int32_t count = 0;
uint64_t totalBytes = 0;
auto numAllocations = rows_.numRanges();
int32_t rowSize = fixedRowSize_;
for (auto i = iter->allocationIndex; i < numAllocations; ++i) {
auto range = rows_.rangeAt(i);
auto* data =
range.data() + memory::alignmentPadding(range.data(), alignment_);
auto limit = range.size() -
(reinterpret_cast<uintptr_t>(data) -
reinterpret_cast<uintptr_t>(range.data()));
auto row = iter->rowOffset;
while (row + rowSize <= limit) { // limit是当前内存块的有效范围,这里也能看出来行数据在内存中是连续存储的
rows[count++] = data + row; // 存储当前行地址至rows(输出)
VELOX_DCHECK_EQ(
reinterpret_cast<uintptr_t>(rows[count - 1]) % alignment_, 0);
row += rowSize;
auto newTotalBytes = totalBytes + rowSize;
if (bits::isBitSet(rows[count - 1], freeFlagOffset_)) { // 当前为已释放的行,跳过,--count保证了下次覆盖写入
--count;
continue;
}
totalBytes = newTotalBytes;
if (rowSizeOffset_) { // 添加变长数据的大小
totalBytes += variableRowSize(rows[count - 1]);
}
if (count == maxRows || totalBytes > maxBytes) { // 如果达到 maxRows 或 maxBytes 的限制,更新迭代器状态并返回
iter->rowOffset = row;
iter->allocationIndex = i;
return count;
}
}
iter->rowOffset = 0;
}
iter->allocationIndex = std::numeric_limits<int32_t>::max(); // 遍历了所有内存块,设置迭代器状态
return count;
}
extractColumn
将行数据按列提取,执行真正的数据拷贝。
调用方式:1
2
3
4
5
6
7for (const auto& columnProjection : columnMap_) {
data_->extractColumn(
sortedRows_.data() + numOutputRows_, // 当前已输出的行数
output_->size(),
columnProjection.inputChannel,
output_->childAt(columnProjection.outputChannel));
}
声明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42// 将 columnIndex 所对应列的值从 rows 中的每一行复制到 result 中。
// 若行中数据为null,则 result 中对应数据也为null。
void extractColumn(
const char* const* rows,
int32_t numRows,
int32_t columnIndex,
const VectorPtr& result) const {
extractColumn(
rows,
numRows,
columnAt(columnIndex),
columnHasNulls(columnIndex),
result);
}
static void extractColumn(
const char* const* rows,
int32_t numRows,
RowColumn col,
bool columnHasNulls,
const VectorPtr& result) {
extractColumn(rows, numRows, col, columnHasNulls, 0, result);
}
inline void RowContainer::extractColumn(
const char* const* rows,
int32_t numRows,
RowColumn column,
bool columnHasNulls,
int32_t resultOffset,
const VectorPtr& result) {
VELOX_DYNAMIC_TYPE_DISPATCH_ALL(
extractColumnTyped,
result->typeKind(),
rows,
{},
numRows,
column,
columnHasNulls,
resultOffset,
result);
}
基本上可以看做是store的逆操作。extractColumn执行宏展开后,大致如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
[&]() { \
if ((typeKind) == ::facebook::velox::TypeKind::UNKNOWN) { \
return TEMPLATE_FUNC<::facebook::velox::TypeKind::UNKNOWN>(__VA_ARGS__); \
} else if ((typeKind) == ::facebook::velox::TypeKind::OPAQUE) { \
return TEMPLATE_FUNC<::facebook::velox::TypeKind::OPAQUE>(__VA_ARGS__); \
} else { \
return VELOX_DYNAMIC_TYPE_DISPATCH_IMPL( \
TEMPLATE_FUNC, , typeKind, __VA_ARGS__); \
} \
}()
[&]() {
if ((result->typeKind()) == ::facebook::velox::TypeKind::UNKNOWN) {
return extractColumnTyped<::facebook::velox::TypeKind::UNKNOWN>(
rows,
rowNumbers,
rowNumbers.size(),
column,
columnHasNulls,
resultOffset,
result);
} else if ((result->typeKind()) == ::facebook::velox::TypeKind::OPAQUE) {
return extractColumnTyped<::facebook::velox::TypeKind::OPAQUE>(
rows,
rowNumbers,
rowNumbers.size(),
column,
columnHasNulls,
resultOffset,
result);
} else {
return [&]() {
switch (result->typeKind()) {
case ::facebook::velox::TypeKind::BOOLEAN: {
return extractColumnTyped<::facebook::velox::TypeKind::BOOLEAN>(
rows,
rowNumbers,
rowNumbers.size(),
column,
columnHasNulls,
resultOffset,
result);
}
...
}
}
}
}
1 | template <TypeKind Kind> |
estimateRowSize
预估值,用于指示每行大致占用了多少内存。1
2
3
4
5
6
7
8
9
10
11
12std::optional<int64_t> RowContainer::estimateRowSize() const {
if (numRows_ == 0) {
return std::nullopt;
}
int64_t freeBytes = rows_.freeBytes() + fixedRowSize_ * numFreeRows_; // free: 当前内存池空闲大小 + 已删除行占用的内存
int64_t usedSize = rows_.allocatedBytes() - freeBytes +
stringAllocator_->retainedSize() - stringAllocator_->freeSpace(); // used: 内存池分配大小 - 空闲大小 + (string allocator分配大小 - 空闲大小)(变长数据占用)
int64_t rowSize = usedSize / numRows_; // 估算得到一行平均需要占用多大字节
VELOX_CHECK_GT(
rowSize, 0, "Estimated row size of the RowContainer must be positive.");
return rowSize;
}
freespace
1 | // 返回在不扩容的前提下,当前rowContainer还能存储 |
sizeIncrement
1 | // 若当前需要追加存储N行 + 变长区还需要M字节,需要多少内存 |