前言
设计基于锁的数据结构的核心要旨:在持有锁时间最短的前提下,访问数据时锁住正确的互斥锁。若使用不同的互斥锁来保护数据结构中不同的部分,操作不当可能会导致死锁,因此更需小心。
使用锁的线程安全栈
代码实例
1 |
|
实例分析
- 线程安全
通过使用互斥锁保护每个成员函数,确保任一时刻均只有一个线程在访问数据。 条件竞争
2.1 在empty和pop成员函数间有潜在的竞争条件(调用empty时是正确的,但其结果并不可靠:其返回后可能其他线程执行了pop操作),但pop在持有锁时将显式地判空,因此条件竞争无影响。
2.2pop函数将直接返回栈顶数据,避免操作分离后top与pop潜在的竞争条件(具体可见线程间共享数据——使用互斥量保护共享数据一章)。异常
3.1 对互斥锁上锁可能会抛出异常,但这种情况不仅极其罕见(互斥锁存在问题,或缺乏系统资源),并且上锁是每个成员函数的第一个操作。由于没有数据被修改,因此异常安全。
3.2 解锁互斥锁不会失败,所以总是安全的,并且std::lock_guard<>确保了互斥锁不会一直处于上锁的状态。
3.3 在第一个重载的pop中,程序可能抛出一个empty_stack异常,由于没有数据被修改,所以是安全的。创建res可能会抛出一个异常,原因可能为:std::make_shared可能因为无法为新对象以及引用计数需要的数据分配出足够的内存而抛出异常,亦或在拷贝/移动数据到新分配内存时构造函数抛出异常。C++运行库与标准库将保证上述两种情况没有内存泄露,同时正确销毁新创建的对象(如有),由于没有数据被修改,因此异常安全。调用data.pop保证不会抛出异常。综上,该pop函数异常安全。
3.4 第二个重载的pop在拷贝赋值或移动赋值时可能抛出异常,但依旧没有数据修改,异常安全。
3.5empty不会修改数据,异常安全。死锁
由于持有锁时调用了用户代码——数据的拷贝/移动构造或拷贝/移动赋值运算符,亦或是自定义的new操作运算符,因此可能出现死锁,例如:
4.1 这些函数调用了栈上的成员函数(而栈正在插入或移除数据项)
4.2 这些函数内部持有一种锁,而在调用栈成员函数时又lock了内部的互斥锁,二者可能存在关联
因此必须令用户保证上述情况不会发生。构造与析构
构造函数与析构函数没有上锁保护,因此可能存在安全问题。但不管并发与否,调用一个不完全构造的对象或是部分销毁的对象的成员函数永远都不可取。因此,用户必须确保2点:
5.1 其他线程直到栈完全构造才能访问它
5.2 在栈对象销毁前,所有线程都已经停止访问栈
实例缺陷
尽管该数据结构安全性很高,但其性能非常差——每次只有一个线程能够操作栈内数据,而其他线程在等待锁时什么也干不了,过度的串行化抑制了性能。
同时,栈也未能提供等待添加一个数据项的方法——因此线程必须周期性地调用empty或pop,并捕获empty_stack异常。这逼迫用户要么浪费宝贵的计算资源来检查数据,要么编写等待——通知机制(如条件变量),这使得内部上锁没有必要。
使用锁的线程安全队列
代码实例1
1 | template<typename T> |
实例1分析
相对栈的实现,主要差别有2点:
- 新增了条件变量,不再需要线程持续调用
empty try_pop不再抛出异常,转为返回bool量
在异常安全性方面存在一个细微变化:由于使用的是notify_one,因此在多线程等待时,只会有一个线程被唤醒。但如果该线程在wait_and_pop中抛出一个异常(如构造std::shared_ptr<>对象时),此时队列不为空,但不会有其他线程被唤醒。若当前使用环境无法接受这种情况,存在三种修改方案:
- 将
notify_one调用可以替换成notify_all,它将唤醒所有的工作线程,代价是大多数线程发现队列依旧是空时将重新进入休眠状态。 - 有异常抛出时令
wait_and_pop调用notify_one,从而让另一个线程尝试检索队列内数据。 - 将
std::shared_ptr<>的初始化过程移到push中,队列由存储数据实例转为存储std::shared_ptr<>实例,由于std::shared_ptr<>拷贝不会抛出异常,由此即可保证异常安全性。
代码实例2
根据方案3,有代码实例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48template<typename T>
class threadsafe_queue {
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T> > data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue() {}
void wait_and_pop(T& value) {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=std::move(*data_queue.front());
data_queue.pop();
}
bool try_pop(T& value) {
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value=std::move(*data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> wait_and_pop() {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
std::shared_ptr<T> res=data_queue.front();
data_queue.pop();
return res;
}
std::shared_ptr<T> try_pop() {
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res=data_queue.front();
data_queue.pop();
return res;
}
void push(T new_value) {
std::shared_ptr<T> data( std::make_shared<T>(std::move(new_value)));
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
bool empty() const {
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
实例2分析
除去解决前文所述的问题外,使用std::shared_ptr<>还有一大优点:push内数据实例的构造可以在锁外完成。一般来说,内存分配的性能开销较大,若将其置于锁内将增加持有锁的时间,不利于数据结构的性能。
使用细粒度锁和条件变量的线程安全队列
上文所提及的两种线程安全数据结构,本质上均为使用互斥锁保护STL容器,尽管易于实现,但其并发程度较低。通过精心设计底层数据结构,开发者可以提供更细粒度的锁定,从而进一步提高并发程度。
基于单链表实现的队列
最简单的队列是单链表,如下图所示。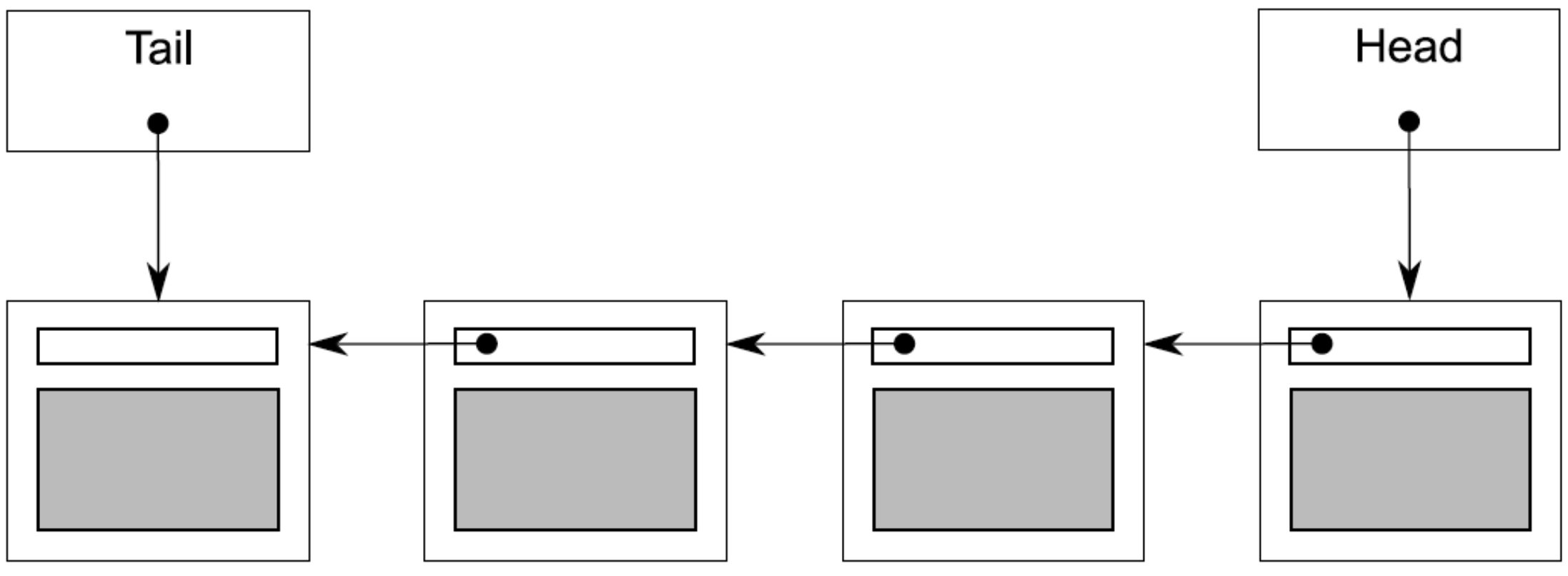
队列维护着一个头指针和一个尾指针,分别指向链表的首项数据与末项数据。push操作为添加新数据为tail的next,并更新tail,pop操作即为更新head为其next,此后切断联系。
当head==tail==nullptr时,链表为空。具体实例如下。
代码实例(单线程版)
1 | template<typename T> class queue |
实例分析
该队列使用了std::unique_ptr<node>来管理节点,从而保证了节点和其引用数据将在不需要时自动删除,tail是指向最后一个节点的裸指针,因为它需要引用std::unique_ptr<node>已经拥有的节点(代码1处p已经被move)。
在多线程下使用细粒度锁时,开发者可能会倾向于使用2个互斥锁分别保护两个数据项head与tail,但存在以下问题:
push可能同时修改head与tail,因此它必须锁住两个互斥锁——虽然很少见,但同时锁住两个互斥锁还不算太诡异。push和try_pop都能访问next指针指向的节点:push更新tail->next,然后try_pop读取head->next。若队列中只有一个元素(head==tail),此时head->next和tail->next是同一个需要保护的对象。若不同时读取head和tail,开发者无法区分它们是否是同一个对象,因此必须在push与try_pop内锁住同一个锁(用来保护next数据)。
实例改进(增加尾部哨兵)
开发者可以通过分配尾哨兵来解决问题,此时tail将不再指向具体数据,而是承担哨兵角色。为了允许哨兵的存在(没有数据),需要增加额外的一层间接性——通过指针来存储数据,具体代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30template<typename T> class queue {
private:
struct node {
std::shared_ptr<T> data; // 1
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
public:
queue():head(new node),tail(head.get()) {}
queue(const queue& other)=delete;
queue& operator=(const queue& other)=delete;
std::shared_ptr<T> try_pop() {
if(head.get()==tail) {
return std::shared_ptr<T>();
}
std::shared_ptr<T> const res(head->data);
std::unique_ptr<node> old_head=std::move(head);
head=std::move(old_head->next);
return res;
}
void push(T new_value) {
std::shared_ptr<T> new_data(std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
tail->data=new_data; // 若tail==head,此时head亦被赋值
node* const new_tail=p.get();
tail->next=std::move(p);
tail=new_tail;
}
};
实例分析
实例比较
构造函数中新增了对虚拟节点的创建
try_pop的改动为:
2.1 将检查head是否为nullptr替换为比较head与tail,因为引入虚拟节点后head将不可能为nullptr。
2.2 直接返回指针,不再需要创建新一个新实例。push的改动为:
3.1 必须先在堆上创建一个T类型的实例,并让一个std::shared_ptr<>拥有该实例。
3.2 将原有哨兵节点数据替换为新实例,连接至新哨兵,并更新哨兵节点。
改进收益
push只需访问tail,不再访问head,这意味着不需要持有2个互斥锁。try_pop与push将永远不可能对同一节点做操作(head->next与tail->next一致时,队列为空,此时直接返回),因此不再需要一个总的互斥锁。
代码实例(加锁)
1 | template<typename T> |
实例分析
设计思路
为了实现最大程度的并发,上锁的时间越少越好。因此push与try_pop有设计思路如下:
- push
访问tail期间均必须完成上锁,因此分配完成性哨兵节点后上锁开始,直至函数完成。 - try_pop
首先必须锁住head,直至head完成改变(该操作决定了哪一个线程执行pop操作)。其次,由于判空需要获取tail,因此在此期间必须完成对tail的锁定。
将pop_head与get_tail封装为函数不仅提高了代码可读性,同时也使得互斥区更加明确。
安全性分析
不变量
针对该基于单链表实现的队列,有不变量如下:
- tail->next==nullptr
- tail->data==nullptr
- head==tail意味着空链表
- 单元素链表有head->next==tail
- x->next==tail意味着x是链表中最后一个节点
- 以head为起点迭代,必将访问至tail
线程安全分析
- push
如前文所述,数据被正确保护,不变量未遭到破坏。 - try_pop
2.1 该函数需要在读取head,tail时加锁以避免数据竞争。如果tail不加锁,则可能出现数据竞争或UB:一个线程调用try_pop的同时,另一个线程调用push,此时可能两个线程在访问同一个tail对象(尽管每个成员函数都加锁了,但pop与try_pop持有的是不同的锁)。加锁后get_tail将会锁住和push相同的锁,因此调用将存在明确顺序:要么get_tail将在push前被调用,线程看到的是tail旧值;要么在push后被调用,线程将观察到tail新值。
2.2get_tail的调用必须发生于head_mutex互斥区内当进入1
2
3
4
5
6
7
8
9
10
11// error version
std::unique_ptr<node> pop_head() {
node* const old_tail = get_tail();
std::lock_guard<std::mutex> head_lock(head_mutex);
if(head.get() == old_tail) {
return nullptr;
}
std::unique_ptr<node> old_head = std::move(head);
head=std::move(old_head->next);
return old_head;
}head_mutex的互斥区后,很有可能tail与head的值已经发生了改变(另一个线程完成了push或者正在调用pop_head修改head),此后的判空无意义。若get_tail在head_mutex保护范围内,即可保证没有其他线程对head进行修改,判空符合预期。
异常安全分析
try_pop锁住互斥锁时可能产生异常,但由于在获得锁前数据不会被修改,因此try_pop异常安全。push在堆上分配数据实例和node实例时(new语句)可能会产生异常,但智能指针保证了异常安全性。获得锁后,push内操作不会产生异常,因此push异常安全。
死锁
pop_head获取锁的顺序永远是先head_mutex再tail_mutex,因此永远不会死锁。
并发性分析
细粒度锁的引入带来了更高的并发性,并且本实例已尽可能将操作置于锁外。举例而言,push中新节点和新数据项的分配都未曾持有锁,这保证了多个线程可以并发地分配新节点新数据项。在try_pop中较为耗时的delete同样置于锁外,这增加了并发调用try_pop的次数。
实例完善(增加wait_and_pop)
本节将针对上述实例做进一步完善,新增wait_and_pop接口,并补充pop接口重载版本。
设计思路
- push
简单来看,只需要在函数末尾添加data_cond.notify_one()调用即可,但此时处于tail_mutex被锁住的状态,若被通知的线程在tail_mutex解锁前醒来,则需要等待该互斥锁解锁,因此可以考虑在调用notify_one前解锁互斥锁以获得最大并发性。 - wait_and_pop
首先,仅有在队列非空时(head != tail)需要等待,因此似乎需要同时锁住两个互斥锁,但正如前文所述(只有在读取时需要持有互斥锁),因此谓词可设定为head!=get_tail()即可,然后使用head_mutex对data_cond.wait()调用进行保护。 - 重载pop
若将从old_head检索得到的数据项拷贝赋值至value,若拷贝赋值操作抛出异常,则数据量将彻底丢失(队列中已不存在数据)。因此必须新增一个重载的pop_head函数,在改动链表前检索数据。
代码实例
1 | template<typename T> |