前言
一段经典的生产-消费场景代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
std::vector<int> data;
std::atomic<bool> data_ready(false);
void reader_thread() {
while(!data_ready.load()) {
std::this_thread::sleep(std::milliseconds(1));
}
std::cout<<"The answer="<<data[0]<<"\n";
}
void writer_thread() {
data.push_back(42);
data_ready=true;
}
这里我们利用原子操作,保证了写入操作必然“先发生于”读取操作。不过,原子操作对顺序要求还有其他选项,它们构成了原子操作间的各种关系,下文将一一说明。
“同步于”
“同步于”关系只能在原子类型的操作间获得。如果UDT(user-defined-type)包含原子类型,并且施加于UDT实例的行为内包含有原子操作(例如锁住互斥锁) 亦可提供这种关系。但本质上,该关系仅与原子操作绑定。
其基本概念为:对于变量x,若当前存在两种操作:一个适当标记(suitably-tagged)的原子写操作W,与一个适当标记的原子读操作R,W “同步于” R。在这种同步关系下,R要么读取到的是W操作写入的内容,要么读取到的是执行W操作的线程内,W操作后续的写操作所写入的值。
由于所有对原子操作类型的操作默认均为适当标记(suitably-tagged),因此我们可以简化“同步于”关系为:如果线程A存储了一个值,并且线程B读取了这个值,则在默认情况下,线程A的存储操作与线程B的加载操作之间有一个“同步于”关系,如图所示: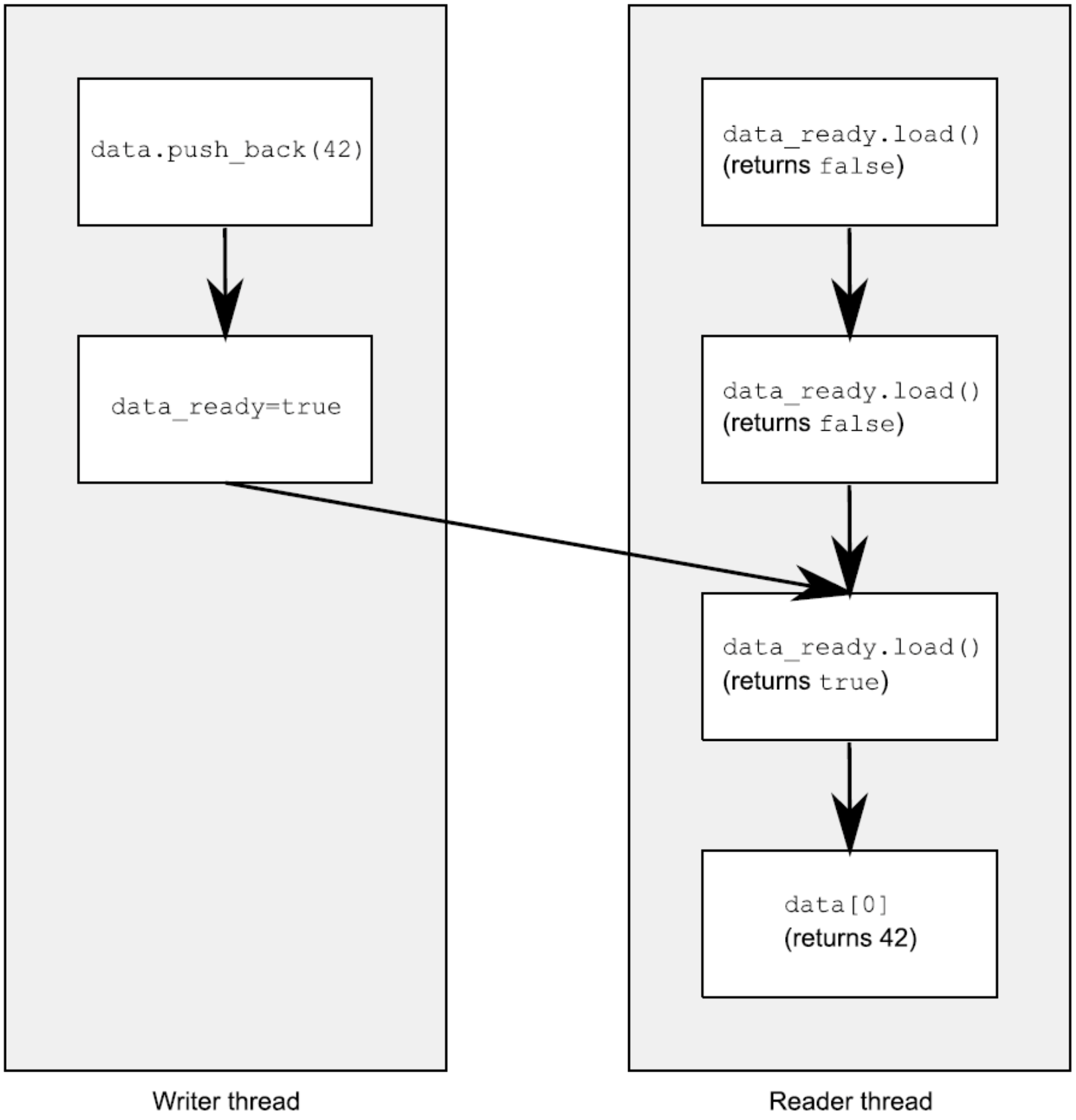
原子操作内的细微差别都来自于“适当标记”部分,C++内存模型允许对原子类型的操作应用各种顺序约束,这就是所谓的标记。
“先发生于”
“先发生于”(happens-before)关系是程序中操作顺序的基础构件——它指定了哪些操作能看见另一些操作的影响。
对于单线程而言,确保“先发生于”关系很简单——只需要在源码中确保操作A先于操作B出现,则存在操作A必在操作B前发生。如果操作A与操作B发生于同一个语句,则不能确保存在“先发生于”关系,例如下述程序可能输出“1,2”或“2,1”。1
2
3
4
5
6
7
8
9
10
11include <iostream>
void foo(int a,int b) {
std::cout<<a<<”,”<<b<<std::endl;
}
int get_num() {
static int i=0;
return ++i;
}
int main() {
foo(get_num(),get_num()); //无序调用get_num(),未定义行为
}
为了避免混淆,我们将单线程内操作A必然发生于操作B之前的关系称为“先序于”(sequenced-before),而将线程间的操作A必然发生另一个线程内操作B之前的关系称为“线程间先发生于”(inter-thread happens-before)。
对于“线程间先发生于”而言,若一个线程内的操作A与另一个线程内的操作B同步,则有A“线程间先发生于”B。该关系具备传递性,即若A“线程间先发生于”B,且B“线程间先发生于”C,则A“线程间先发生于” C。
“线程间先发生于”亦可和“先序于”相结合:若操作A“先序于”操作B,且操作B“线程间先发生于”操作C,则有A“线程间先发生于”C。类似地,如果 A“同步于”B,且B“先序于”C,则A“线程间先发生于”C。
原子操作的内存顺序
正如前文已经提及到的,原子操作共计可以指定六种内存顺序,默认使用memory_order_seq_cst(最严格):
- memory_order_relaxed
- memory_order_consume
- memory_order_acquire
- memory_order_release
- memory_order_acq_rel
- memory_order_seq_cst
尽管内存顺序存在六种,但它们仅代表三种内存顺序模型:
- 序列一致 (sequentially consistent)
- 获得-释放 (acquire-release):memory_order_consume, memory_order_acquire, memory_order_release,memory_order_acq_rel
- 宽松 (relaxed):memory_order_relaxed
不同的内存顺序模型在不同的CPU架构下成本不同。举例而言,在基于通过处理器精细控制操作可见性的架构(而非更改可见性的架构)的系统上,“序列一致”顺序相较于“获得-释放”或者“宽松”需要额外的同步指令,“获得-释放”顺序相较于“宽松”也是如此。如果这些系统有很多处理器,额外的同步指将会花费大量的时间,从而降低系统整体性能。另一方面,使用x86或x86-64架构的CPU(比如使用Intel或AMD处理器的台式电脑) 除了执行确保原子性所必须的指令之外,不需要为“获得-释放”执行额外指令,甚至“序列一致”对于加载操作也不需要任何特殊处理,尽管在数据存储层面增加了些许成本。
不同内存顺序模型保证了开发者得以使用更细粒度的顺序关系对程序性能做出提升,下文将依介绍它们的特点及应用范围。
序列一致
序列一致是最容易被理解的内存顺序,因此C++将其定义为默认内存顺序。若原子类型实例上的所有操作均遵循“序列一致”的,则多线程程序的行为将类似于所有操作都是由单个线程按照某种特定的序列执行的——所有线程必须看到相同的操作顺序,不允许存在重新排序的操作。这种约束不适用于使用“宽松”内存顺序原子操作的线程——它们仍然可以看到不同顺序的操作,因此必须在所有线程上使用“序列一致”的操作,才能受益。
下述代码演示了这种顺序约束的作用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x() {
x.store(true,std::memory_order_seq_cst);
}
void write_y() {
y.store(true,std::memory_order_seq_cst);
}
void read_x_then_y() {
while(!x.load(std::memory_order_seq_cst));
if(y.load(std::memory_order_seq_cst))
++z;
}
void read_y_then_x() {
while(!y.load(std::memory_order_seq_cst));
if(x.load(std::memory_order_seq_cst))
++z;
}
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
assert(z.load()!=0);
}
assert语句将永远无法触发,因为必将发生存储x或存储y(虽然未指定哪一个)。若在read_x_then_y中加载y返回false(存储x的操作发生在存储y的操作之前),则read_y_then_x中加载x必定会返回true(while循环将保证此刻y已为true)。因为memory_order_seq_cst语义需要在所有标记为memory_order_seq_cst的操作上有一个单一全序,因此在“加载y返回 false”与“存储y”的操作之间存在一个隐含的顺序关系。由于单个全序,当一个线程看到x==true,随后又看到y==false,即意味着在此全序中存储x的操作发生在存储y的操作之前。当然,这个假设是对称的,亦可能存在完全相反的情况,此时先存储y后存储x。
从同步的角度来看,一个“序列一致”的存储操作“同步于”相同变量的加载操作,这个加载操作读取存储的值,这为两个(或更多)线程的操作提供了一个顺序约束,但“序列一致”的约束性比上述描述的更强。对系统中使用“序列一致”原子操作的其他线程,任何加载操作之后执行的“序列一致”的原子操作也必须出现在存储操作之后。
针对read_x_then_y看x为true,且y为false的情况,有图例如下。虚线展示了为了保持“序列一致”而隐含的必须的顺序关系——在 memory_order_seq_cst操作的全局顺序中,为了获得这里给出的结果,加载操作必须在存储操作之前发生。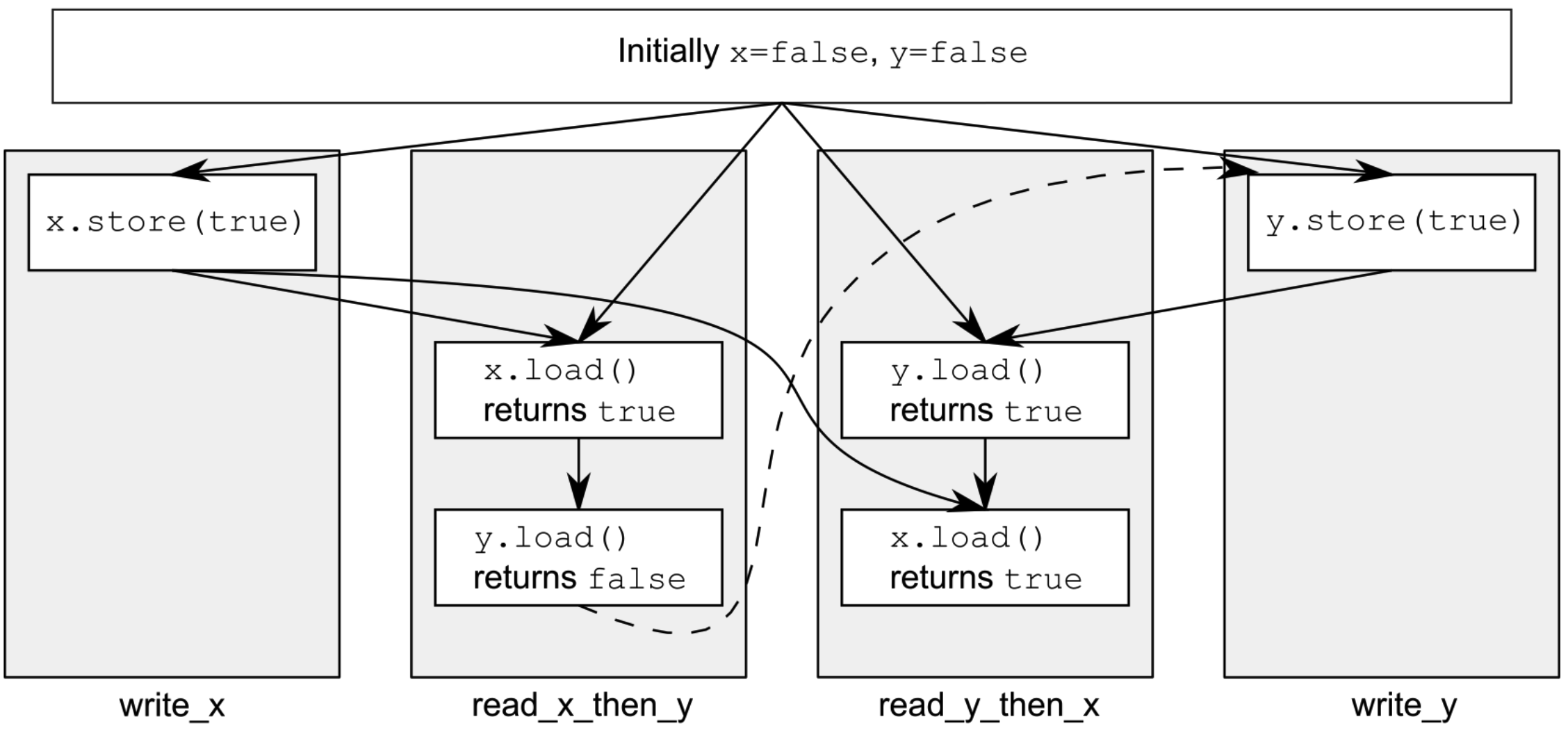
“序列一致”是最简单直观的顺序,也是最昂贵的内存顺序,因为它需要所有线程间进行全局同步。在一个多处理器系统上,这可能需要在处理器之间进行大量并且耗时的通信。
非序列一致
宽松
原子类型上的操作以宽松顺序执行时,不会参与任何“同步于”关系。在同一线程内,对于同一变量的操作服从“先序于”关系。而线程间几乎没有任何顺序要求,唯一特例是线程访问单个的原子变量不能重排——当线程看到一个原子变量的特定值后,该线程随后的读操作将无法检索到这个变量更早的值。以下代码实例将展示宽松顺序的影响。
1 |
|
这次assert可能会触发,因为加载x的操作可能读取到false,即使加载y的操作读取到true,并且存储x的操作“先发生于”存储y的操作。由于x,y是不同的变量,因此各操作对其数据可见性并不做顺序性保证。
宽松顺序对于不同变量可以自由重排,只需遵守约束“先发生于”关系即可(例如读取到y为true后,仅能保证接下来该线程不会读取到y为true之前的值),它不会引入“同步于”关系。尽管在存储与存储,加载与加载操作间存在着“先发生于”关系,但存储和加载间并不存在这种关系,因此载入操作可以看到次序颠倒的存储操作,下图展示了这种关系。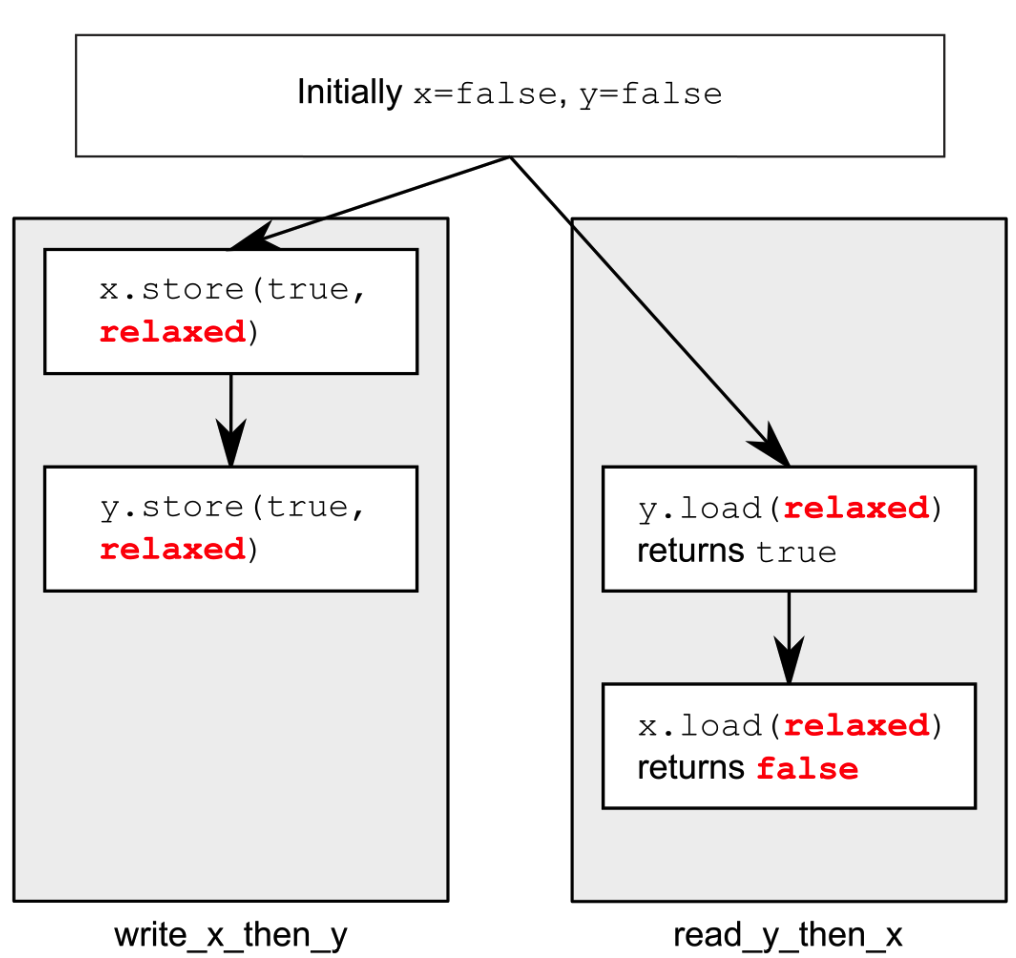
问题实例
接下来关注一个略微复杂点的实例:
1 |
|
该程序内有三个全局原子变量和五个线程。每一个线程循环10次,使用memory_order_relaxed读取三个原子变量的值,并且将它们存储在一个数组上。其中三个线程每次通过循环来更新其中一个原子变量,而剩下的两个线程负责读取。当线程都被joined了,则打印出每个线程存到数组上的值。如果没有明确的延迟,第一个线程可能在最后一个线程开始前结束,因此使用原子变量go来确保线程尽可能接近同一时间开始循环。一旦go被设定为true,则所有线程均将开始执行。
该程序一种可能的输出如下:1
2
3
4
5(0,0,0),(1,0,0),(2,0,0),(3,0,0),(4,0,0),(5,7,0),(6,7,8),(7,9,8),(8,9,8), (9,9,10) // increment
(0,0,0),(0,1,0),(0,2,0),(1,3,5),(8,4,5),(8,5,5),(8,6,6),(8,7,9),(10,8,9), (10,9,10) // increment
(0,0,0),(0,0,1),(0,0,2),(0,0,3),(0,0,4),(0,0,5),(0,0,6),(0,0,7),(0,0,8), (0,0,9) // increment
(1,3,0),(2,3,0),(2,4,1),(3,6,4),(3,9,5),(5,10,6),(5,10,8),(5,10,10), (9,10,10),(10,10,10) // read
(0,0,0),(0,0,0),(0,0,0),(6,3,7),(6,5,7),(7,7,7),(7,8,7),(8,8,7),(8,8,9), (8,8,9) // read
我们可以关注到几点:
- 线程1中x每次增1,线程2中y每次增1,线程3中z每次增1。
- 在给定输出集合中,x,y,z均为不均匀增序,且相对顺序在各线程中不同。
- 线程3只关注到了z的更新,无视x与y的更新,但不影响其他线程可以关注到z的更新。
类比分析
想象每个原子变量是一个小隔间里的办事员,它拿着小本子记录着一个列表(变量值的历史版本)。当你要一个值的时候,它就从列表中取出一个值给你(load),如果你想写入一个值,那它就把这个新值写在列表的最后(store)。
当然,读取值是有一定规则的。当你第一次向它获取值时,它可能会给你列表中的任意值。此后如果你继续要,它可能会给你同一个值,或者出现在该值后的任意值。如果你写入一个值后再向它要一个值,则要么给你你写入的值,要么给你出现在该值后的任意值。(先发生于)
举个例子,若它的列表上开始有5,10,23,3,1,2这几个值。如果你问他要一个值, 你可能获取这几个数中的任意一个。假设它给你10,那么下次再问它要值的时候可能会再给你10,或者10 后面的数,但绝对不会是5。如果连续要5次,它可能回复“10,10,1,2,2”。如果你要它写下42,则它会将列表更新为“5,10,23,3,1,2,42”,此后将只会向你提供42这个值,直到有新值被写入后它才有可能给你新值。
现在让情况复杂一些——假设当前存在多个人对这个可怜的办事员发号施令,但它一次只能处理一个人的请求,为了确保能保证每个人拿到的新值都符合上述规则,它选择使用一个便利贴指向各个值,用以标识当前各人的所了解到的列表状态,具体如下图所示: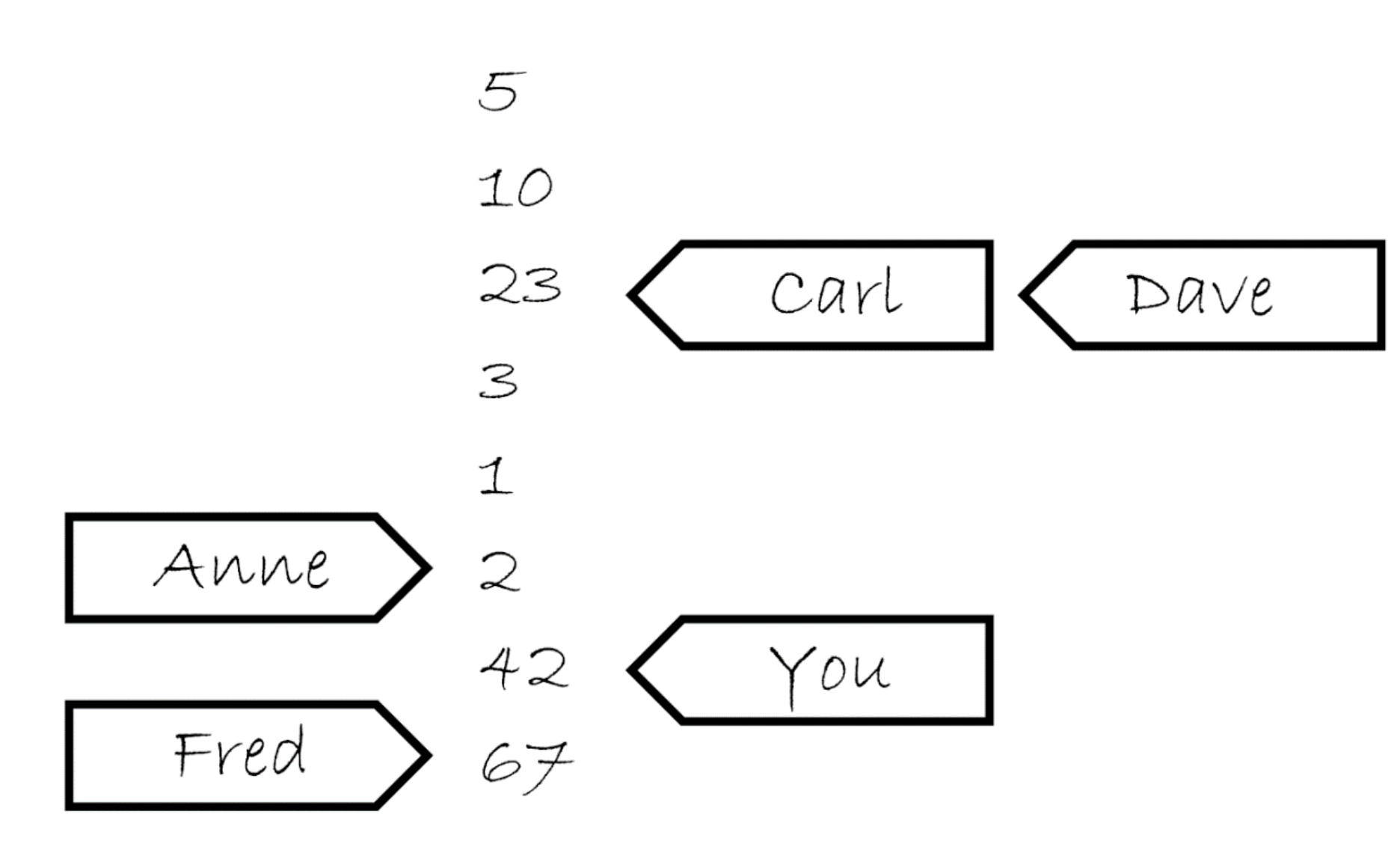
那么上一个实例的输出就很容易理解了——write_x_then_y函数就类似于A通知x办事员写下 true,之后又通知y办事员写下true。线程反复运行read_y_then_x就类似于B反复向y要值,直到它说true,然后再向x要值。x没必要告诉B最新值true,它完全有可能告诉B false。
除此之外,该办事员也支持一些其他操作,例如“写下这个数字,并且告诉我现在列表中的最后一个数字”(exchange),或“当列表的最后一个数字为某值则写下这个数字;否则的话,告诉我我试图去猜的值(此时已经未必是列表最后一个)是多少”(compare_exchange_strong)。
获取—释放
“获得-释放”是“宽松”的增强版——在不存在全序操作的前提下引入了同步。在这种顺序模型中,原子加载是获得(acquire)操作(memory_order_acquire),原子存储是释放(memory_order_release)操作,原子读-改-写操作(如fetch_add或exchange可以是“获得”/“释放”中的任意一个,或者两者兼备 (memory_order_acq_rel),一个“释放”操作同步于一个“获取”操作。
代码实例1
1 |
|
这里assert可能会触发,因为可能加载x和y的时候都读取到的是false。下图展示了程序的一种可能运行流程: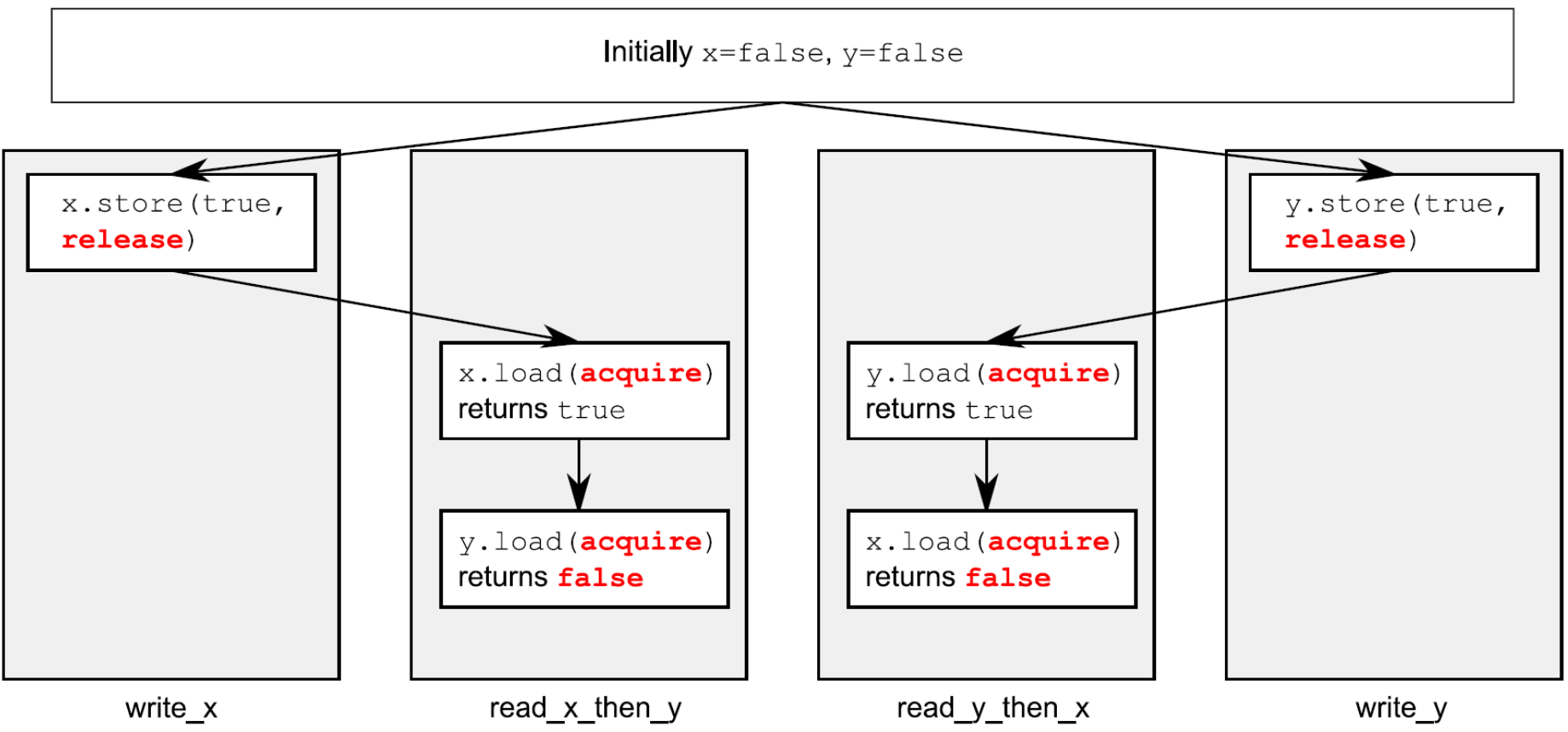
代码实例2
获取-释放的正确使用实例如下文所示——将两次存储由一个线程来完成,存储y时使用std::memory_order_release,读取y时使用std::memory_order_acquire:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y() {
x.store(true,std::memory_order_relaxed);
y.store(true,std::memory_order_release);
}
void read_y_then_x() {
while(!y.load(std::memory_order_acquire)); // 自旋,等待y被设置为true
if(x.load(std::memory_order_relaxed))
++z;
}
int main() {
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert(z.load()!=0);
}
由于y的存储/读取操作存在“同步于关系”,而x,y的存储操作又在一个线程,存在”先序于”关系,因此,当read_y_then_x中的y被读取为true时,x必然为true,此时将导致z自增,此时assert将不会触发。为了提供同步,std::memory_order_acquire与std::memory_order_release必须成对进行。
类比分析
同样以办事员举例,获取-释放操作需要在此前的建模中引入“批次”的概念。具体而言,每个已经完成的存储都是某一批次更新的一部分,因此,你在告诉办事员数值时,必须提及“请记下99,作为第423批的一部分”,一个批次中的末尾存储需要说明为“请记下127,作为第423批的最后存储”。此后的存储将变为424批次。
获取值则分为2种情况:
- 简单请求一个值(宽松),此时办事员给你提供一个值
- 请求一个值,并且希望了解它是否是某批次中的最后一个(获取-释放)。若该值不是批次中的最后一个,办事员会说它是个普通值,否则它将提供如下信息:“数字为987,该值是956批次的最后一个,来源于Anne”。这即是获取-释放的核心操作:当你向办事员提供了你所了解的批次后,它会在其列表中查找该批次的最后一个值,然后要么给你该值,要么给予更靠后的值。
那么我们将根据上述原则分析代码实例——首先,线程a运行write_x_then_y,告知办事员x“请写下true作为来自线程a的批次1的一部分”,然后,线程a告诉办事员y,“请写下true,这是来自线程a的批次1的最后一个写”。与此同时,线程b正在运行read_y_then_x,线程b持续向办事员y请求一个带批次信息的值(std::memory_order_acquire),直到获取true,此时办事员y将告诉线程b,该值为来自线程a批次1的最后一次写。线程b继续向办事员x请求一个值,但这次他会说“请给我一个值,并且我从线程a了解到了批次1”。 此时办事员x将不得不查看它的记事本,从中找到批次1的最后一个写入操作——true。
用“获得-释放”传递同步
正如前文所述,若A“线程间先发生于”B,且B“线程间先发生于”C,则有A“线程间先发生于”C。这意味着“获得-释放”可用于在若干线程间同步数据,即使“中间”线程没有接触到数据。
具体而言,若当前存在三个线程:线程A修改一些共享变量,并对同步变量a执行“存储-释放”(store-release)。线程B使用“加载-获得”(load-acquire)读取“存储-释放”的同步变量a,并对第中同步变量b执行“存储-释放”。线程C对变量b执行“加载-获得”,若线程C确保自己读取到了b“存储-释放”后的值,则线程C此时对共享变量的读取必然也是“存储-释放”后的值:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
int data[3];
std::atomic<bool> sync1(false),sync2(false);
void thread_1() {
data[0] = 42;
data[1] = 97;
data[2] = 17;
sync1.store(true,std::memory_order_release);
}
void thread_2() {
while(!sync1.load(std::memory_order_acquire));
sync2.store(true,std::memory_order_release);
}
void thread_3() {
while(!sync2.load(std::memory_order_acquire));
assert(data[0]==42);
assert(data[1]==97);
assert(data[2]==17);
}
int main() {
for (int i = 0; i < 1000; ++i) {
memset(data, 0 ,sizeof(int) * 3);
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join();
b.join();
c.join();
}
return 0;
}
实际上,我们可以对上述实例做进一步的改进,利用std::memory_order_acq_rel特性使得同步变量仅需要一个即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15std::atomic<int> sync(0);
void thread_1() {
//
sync.store(1, std::memory_order_release);
}
void thread_2() {
int expected=1;
// 反复查看sync是否为1,否则以其值更新expected,是则存入2
while(!sync.compare_exchange_strong(expected, 2, std::memory_order_acq_rel))
expected=1;
}
void thread_3() {
while(sync.load(std::memory_order_acquire) < 2);
// ...
}
“获得-释放”与memory_order_consume的数据相关性
(C++17明确建议不要使用memory_order_consume, 若有兴趣,可直接查阅原文)
“释放序列”与“同步于”
释放序列定义:若存储操作被标记为memory_order_release,memory_order_acq_rel或memory_order_seq_cst,加载操作被标记为memory_order_consum, memory_order_acquire或memory_order_sqy_cst,并且操作链上的每个操作加载的值是由前面的操作写入的,那么操作链就构成了一个释放序列(release sequence)。
释放序列性质:最初的存储“同步于”最终的加载操作,操作链上的任何原子“读-改-写”操作可以拥有任意的内存顺序(memory_order_relaxed)。
代码实例
考虑以atomic<int>对象作为对共享队列内条目数的计数器:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
std::vector<int> queue_data;
std::atomic<int> count;
void populate_queue() { // init
unsigned const number_of_items=20;
queue_data.clear();
for(unsigned i = 0; i < number_of_items; ++i) {
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release);
}
void consume_queue_items() {
while(true) {
int item_index;
// fetch返回操作前的值
if((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0) {
wait_for_more_items();
continue;
}
process(queue_data[item_index - 1]);
}
}
int main() {
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
}
重点关注fetch_sub的内存顺序是std::memory_order_acquire,这意味着该加载操作与之前的存储操作构成了同步关系, 显然,若仅有一个消费者线程时不会发生任何问题。若存在两个消费线程,第二个fetch_sub操作将看到第一个线程写入的值,而不是store写入的值。若没有释放序列的性质,第二个线程与第一个线程不会存在“先发生于”关系,因此可能读到错误的count值,除非第一个fetch_sub具备memory_order_release语义,但这为两个消费者线程引入了不必要的同步关系。不过,第一个fetch_sub()存在于“释放序列”中,所以store能同步于第二个fetch_sub操作,两个消费者线程间仍然不存在“同步于”关系。下图虚线展示了“释放序列”,实线展示了“先发生于”关系: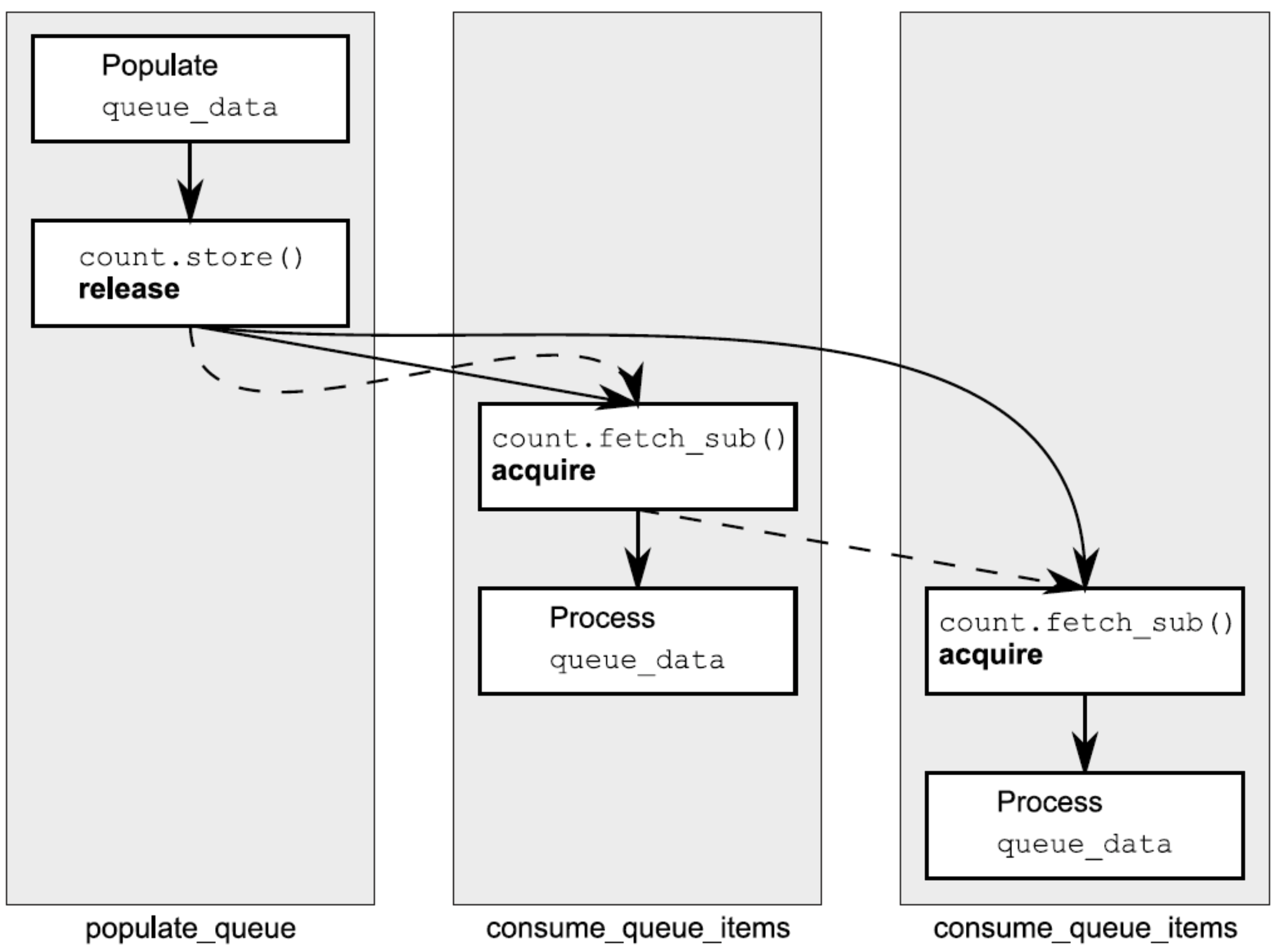
栅栏
栅栏通常也被称为“内存屏障”(memory barriers),可以在不修改任何数据的情况下强制执行内存顺序约束,通常配合std::memory_order_relax使用。正如前文所述,不同变量上的宽松操作通常可以被编译器或者硬件自由地重排,栅栏限制了这种自由度并引入了“先发生于”和“同步于”关系。
代码实例
1 |
|
代码1“同步于”代码2,因此当y为true时,x已经存储为true,此时assert将不会触发。在栅栏上施加“获取-释放”将在代码内引入“同步于”关系。
使用原子操作对非原子操作排序
(本节的主题是通过“获取-释放”引入“同步于”关系,从而保证非原子操作得以排序,实际上,本节大部分relax操作可以直接被替换为非原子操作)
1 |
|
(以上是我本人写的示例代码,但是对while(!y)存疑,是否可能由于编译器优化造成死循环?clang下未发生死循环情况,运行符合预期)
互斥锁实现解析
非原子操作同样遵循“先发生于”传递关系——如果一个非原子操作“先序于”一个原子操作,并且这个原子操作“先发生于”另一个线程中的操作,那么这个非原子操作也会“先发生于”另一个线程中的那个操作,以下述代码实现的简单自旋锁为例(上一篇介绍原子类型时曾经提及):1
2
3
4
5
6
7
8
9
10
11class spinlock_mutex {
std::atomic_flag flag;
public:
spinlock_mutex(): flag(ATOMIC_FLAG_INIT) {}
void lock() {
while(flag.test_and_set(std::memory_order_acquire)); // 忙-等待
}
void unlock() {
flag.clear(std::memory_order_release);
}
};
显然,该自旋锁在内部构成了“释放-获取”顺序,从而可以保证在非原子操作间引入“同步于”关系。当持有锁的线程完成对保护数据的修改后调用unlock——即调用带有 std::memory_order_release语义的flag.clear(),该操作“同步于”随后对flag.test_and_set()的调用——即另一个线程调用lock。对保护数据的修改必然“先序于”unlock,因此将“先发生于”随后第二个线程对lock的调用。值得注意的是,第二个线程获得锁同样“先序于”该线程对保护数据的任何访问。
尽管其他互斥锁的实现各有差异,但基本原理是一样的:lock是一个内部内存位置上的获得操作,unlock是同样的内存位置上的一个释放操作。